IPFS的分布式存储或成为未来趋势
 浪花财经
浪花财经我们正面临云时代的终结,这是一个很大胆的论调,甚至有一些疯狂,但请耐心看完下面的内容。
亚马逊、谷歌、微软以及阿里云正在为它们的云产品添加多层工具,运行软件在服务器上变得来越简单方便,因此在AWS,GCP或Azure中托管代码似乎是最好的方式 - 它是方便、便宜、易于完全自动化并且可以弹性扩展...我们可以继续使用它们。那么,为什么我还会预言云时代的终结呢?
云产品存在的问题
云无法满足长期的伸缩性需求。在云端构建一个可伸缩、可靠、高可用的 Web 应用程序其实是很困难的。就算你做到了,那也是以耗费大量金钱和精力为前提。如果你的业务开展得非常成功,最终还是会受到云和 Web 本身能力的限制:计算机的计算速度和存储容量比网路带宽本身增长得更快。或许这对大多数公司(Netflix 和 Amazon 除外)来说并不是个大问题,但很快就会成为问题。通过网络传输的数据在急速增长,视频的分辨率在提升,需要传输的数据量越来越大,而且很快就会有 VR 数据集在网络上传来传去。

这个问题与 Web 结构本身有直接的关系。获取内容的客户端远比提供内容的服务器多。比如,有人在 Slack 上张贴了一张有趣的小猫图片,和我坐在同一个地方的其他 20 个人都对这张图片感兴趣,所以我们每个人都从服务器上把图片下载下来,那么服务器就需要发送 20 次图片。
如果将服务器移动到云端,那么靠近用户的网络需要处理无法预测的吞吐量。除此之外,还需要海量硬盘来保存这些数据,以及使用很多的 CPU 将数据推送给每一个用户。随着流服务的增长,这种情况会更加严峻。
这些活动需要大量的能源和冷却机制,让整个系统变得低效、昂贵,甚至给自然环境带来污染。
集中式的结构让系统变得脆弱。集中式的数据存储和程序在可用性和性能方面存在不足。如果 Amazon 的数据中心发生洪灾、被小行星撞毁或遭遇龙卷风该怎么办?或者轻微一点,比如发生了短暂的电力故障?机器上保存的数据就无法被访问,甚至永久丢失。
我们一般会把数据保存在多个地方来降低这种问题发生所造成的危害,但那样就需要更多的数据中心。或许使用多个数据中心会极大降低事故风险,但那些非常重要的数据仍然可能丢失,比如婚礼视频、孩子成长的照片或者像 Wikipedia 这类非常重要的公共信息资源。这些资源全部保存在云端——Facebook、Google Drive、iCloud 或 Dropbox 等。如果这些服务哪天失去资金支持,那么这些数据该怎么办?即使这种情况不会发生,要访问这些数据仍然有诸多限制,比如你要通过他们的服务才能访问到这些数据,即使你把它们分享给你的朋友们,他们也仍然需要通过这些服务来访问这些数据。
云服务提供了信任机制,但并不保证绝对安全。你的朋友只能信任经由受信任的中间人发送给他们的数据,这在大多数情况下是没有问题的,但网站和网络是由国家注册的合法实体进行运营的,机构完全有权力迫使他们做一些出格的事情。大多数时候,这样做会是一件好事,因为可以借此帮助解决犯罪问题或者移除网络上的不合法内容,但如果这种权力被滥用了就会走向另一面。
就在几周前,西班牙通过手中的权力停止了加泰罗尼亚地区的一次独立公民投票活动,他们封锁了与投票相关的网站。在中国,通过封锁麻烦网站和秘密修改用户内容这种行为是很常见的。即使在自由言论不成问题的西方国家,也仍然需要努力让互联网变得更加自由和开放,保证用户看到的内容就是作者要发布的。这让我们感到坐立不安。高度集中的互联网最可怕的地方在于私人数据的堆积。大公司为我们提供了各种服务,同时坐拥大量的用户数据,他们通过这些数据预测你将会购买什么商品、将会把手中的选票投给谁、可能什么时候会买房子,甚至预测你想要几个孩子。
或许你会觉得这没什么问题,毕竟你是相信他们才愿意把信息透露给他们,但你要担心并不是他们,而是另有其人。今年早些时候,信用报告机构 Equifax 经历了有史以来最大的一次数据外泄事故,泄露了 1 亿 4 千万客户的信息。如果我们能够再小心一些或许可以避免这类问题的发生,但很显然,数据泄露是无法完全避免的,而且一旦发生了就无比危险。唯一可以防止这类情况发生的办法就是在一开始就不要如此大规模地收集数据。
那么,什么将取代云?
基于 CS 模式(如基于 HTTP 协议的客户端与服务器端交互)的互联网和依赖集中式认证实体的安全机制(比如 TLS)很容易出现一些难以解决的问题,所以我们需要找到一种更好的模式,在这个模式里,没有人会把你的个人数据保存起来,大媒体文件通过整个网络进行传播,形成一个完全点对点和无服务器的系统(这里说的“无服务器”不是指云端的无服务器架构,而是指真的没有服务器存在)。通过广泛了解这方面的新兴技术,我确信点对点技术就是我们的方向。点对点 Web 技术旨在通过一些协议和策略替换掉已有的 Web 构件块,解决上述的大部分问题。点对点技术的目标是形成一个完全分布式、持久、冗余的数据存储,网络中的每一个客户端都保存了数据的部分副本。如果你之前听说过 BitTorrent 技术,那么也应该很熟悉下面的内容。网络用户通过将大文件拆分成小文件(每个小文件都有一个唯一 ID)进行分享,不需要集中式认证实体。如果要下载一个文件,只需要提供文件的散列值。BitTorrent 客户端会找到持有该文件片段的对等节点,并将文件片段下载下来,直到找到所有的文件片段。那么我们该如何找到对等节点?BitTorrent 使用了一种叫作 Kademlia 的协议,网络里的每个节点都有一个唯一 ID,与数据块 ID 的长度一样。每个数据块被保存在一个节点上,这个节点的 ID 与数据块 ID 最为接近。数据块 ID 并不是随机生成的,而是使用了数据块内容的散列值,相当于数据块内容的指纹,所以数据块可以通过散列值进行寻址,并可以通过重新计算和比较散列值来验证数据块内容。因为数据块内容是唯一的,所以就不会下载到与原先内容不一样的数据。更有意思的是,通过将散列值内嵌到另一个数据块里,就可以实现数据块链接。如果链接的数据块被篡改,它的 ID 也会发生变化,那么链接就会失效。而如果内嵌的链接被篡改,那么包含链接的数据块 ID 也会发生变化。通过这种内嵌 ID 链接的机制可以生成数据块链,甚至是更复杂的结构,比如有向无环图,简称 DAG。这种链接也被称为 Merkle 链接,以发明者 Ralph Merkle 的名字命名。Git 仓库就是一个 Merkle DAG 的例子,Git 将提交历史和所有的目录及文件保存成数据块,并分布成一个很大的 Merkle DAG。这又引出了另一个有关分布式存储可寻址内容的属性:它们是不可变的。数据块内容是不可变的,修改过的版本会单独保存,不同修订版但内容没有发生变化的数据块会被重用,因为它们拥有相同的 ID。这就意味着,在这个系统里,不会出现重复的文件。所以,在这个新的 Web 系统里,同样的小猫图片只会存在一个副本。借助 Kademlia 协议、Merkle 数据块链和 Merkle DAG,我们可以构建出结构化的文件模型和修订时间线,并在大规模的对等网络里共享数据。现在已经有一些协议在使用这三项技术构建分布式的存储,比如 IPFS。
IPFS是什么?
星际文件系统IPFS是一个面向全球的、点对点的分布式版本文件系统,目标是为了取代目前统治互联网的超文本传输协议(HTTP),它将所有具有相同文件系统的计算设备连接在一起,让互联网速度更快、更安全、更健壮、更持久。
IPFS分布式存储几大优点
第一:去中心化经济学中有一个著名的理论叫做:不要把鸡蛋放在同一个篮子里,我们可以想象,当下流行的各类云储存都是基于一个中心化的服务器,所有用户把自己的数据都存放在这个服务器里,就像把鸡蛋都放在一个篮子里一样,一旦篮子破了,那么后果不堪设想。IPFS是对云存储的一种升级革新,它的分布式存储不是简单的将数据多分布在几个机房,而是构建了一张覆盖全球的网络,在这张网络中建立无数点对点的节点。
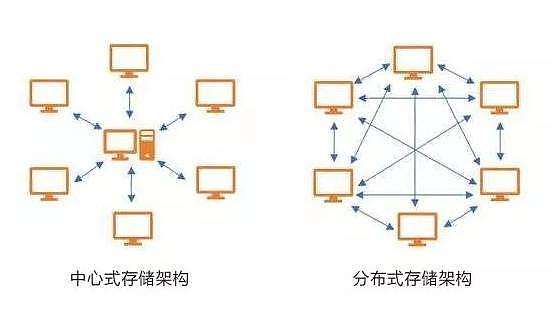
第二:加密数据存储在IPFS网络节点上的数据不是整个地存储,而是被切分成若干的数据块并且经过加密后,再分散到不同的节点中进行存储,这也更有利于保护用户的隐私。第三:数据的所有权存储在IPFS网络上的文件数据,由于其加密性,是无法被被人篡改和删除的,数据的所有权仅仅属于数据的存储者。第四:数据的备份数量和存储时间期限IPFS还发行了自己的代币Filecoin,作为激励层的应用,与IPFS存储相呼应,互相促进发展。用户只要支付足够的Filecoin给代存储的矿工们,那么所备份的文件数据想备份多少,存储多久是没有限制的。第五:及时反馈IPFS设计了机制,是矿工定时向用户提交反馈的存储证明,向用户证明自己百分之百地完成了数据的存储。第六:代币FilecoinFileCoin被提议作为一种创建去中心化存储网络的方法,通过使用IPFS协议,通过FileCoins(FIL)使用周围未使用的存储并激励用户成为共享经济的一部分。IPFS目前仍然处于发展早期阶段,但它的前景非常光明。IPFS融合了一些最前沿的技术,这些技术进展使互联网及其数据网络更加安全、稳健、快速,相信IPFS在未来的分布式存储上将有所作为。