LongHash数据科学家:如何挖掘链上数据的价值?
 浪花财经
浪花财经本次直播是HashBang&CYBEX主办的「加密货币的交易生态」系列直播的第七期。
HashBang 致力于为区块链行业提供知识服务,目前已出品付费课程《激励设计:加密经济学到token经济》、《从小白到大白:重新认识区块链》、《稳定货币:区块链的第三次落地应用》等专栏课程。还有免费的在线公开课《数字货币的量化交易》、《加密货币交易生态》、《加密经济学中的激励设计》,马上5月7号上线Staking的系列直播,大家敬请期待啦!
主题:如何挖掘链上数据的价值
主讲人:吴咸樾
LongHash数据科学家
英国伯明翰大学博士
长期从事比特币、以太坊、EOS、波场等主流区块链数据的挖掘与分析报道
曾任华为5G研究工程师和埃森哲数据科学家
以下是AMA正文:
Q1:上周我们也聊到交易数据,吴博士可以先说说什么是链上数据,跟上周我们聊到的交易数据有什么区别吗?
链上数据就是写到区块链上的数据,它是一种结构化数据,但是它的形式比较复杂。我们以比特币的区块来说明。
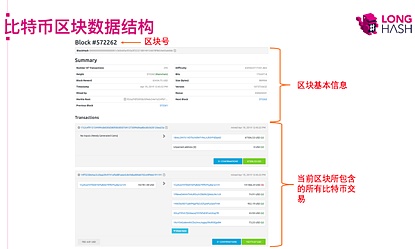
每一个区块首先会有一个区块号,其次会包含一些区块的基本信息,例如当前区块的哈希值,前一个区块的哈希值,当前区块的时间戳以及当前区块所包含的交易笔数等。最后就是区块里的每笔交易的详细信息,这里就包括交易的哈希值,转入地址,转出地址,转账金额等信息。这里需要说明的是,由于比特币采用的是UTXO模型,它的交易可能包含多个转入地址和多个转出地址。但是像以太坊这样采用账户模型的区块链只会有一个转入地址和一个转出地址。
另外,由于以太坊支持智能合约,交易里可能还会包括一些智能合约相关的信息,比如创建一个智能合约,调用智能合约等操作都会上链。这些信息同时也增加处理和分析链上数据的难度。
我们再来看看链上数据的数据量,这取决于区块链本身的活跃度以及所采用的共识机制。比特币的共识算法是工作量证明,大约10分钟产出一个区块,当前每个区块大小约为1MB,一天时间比特币区块链就会增加144MB的数据;以太坊大概每10秒出一个区块,当前每个区块约20KB,因此,以太坊一天会增加约173MB的数据。
链上数据分析的重点与难点是挖掘账户/地址之间的关联关系。下图是根据FBI掌握的“丝绸之路”的比特币的地址而画出的与其关联的比特币交易网络。图中的节点就是比特币地址,图中的边就是一笔转账交易。可以看到,区块链上形成的是一个非常复杂的网络状数据,再加上区块链的匿名性,深度的链上数据挖掘是十分困难的,需要用到大规模网络分析和机器学习等方法。

交易行情数据都是时间序列数据,包括tick行情,K线,市场深度,历史逐笔成交等。交易数据的数据结构相对简单,但是粒度更细。一般交易所每500毫秒就会推送最新的tick数据。此外,我们还会遇到一些非结构化数据的分析,比如区块链项目里的白皮书,或者通过社群里的发言来判断大众对当前行情是看涨还是看跌。这些就需要用到自然语言处理的技术了。
Q2:在这之前,我只知道在以太坊浏览器上查阅一些地址和转账情况,站在专业的角度,这些数据还有什么样的价值存在,您还从哪些地方去抓取到一些链上数据?数据收集起来怎么做建模,可以简单举例说说吗?
首先,我先简单介绍一下链上数据分析的一些基本方法和步骤。要做链上数据分析第一步是获取数据。现在基本上每一个主流区块链都有自己的区块链数据浏览器。比如比特币的bitinfocharts.com,以太坊的etherscan.io,EOS的eosflare.io,以及波场的tronscan.org等。有些浏览器也提供数据的API接口,我们可以直接通过调用接口来获取数据。但是这些网站通常有访问限制且访问速度比较慢,如果需要爬取大量数据就比较困难。快速系统的获取链上数据的方法是搭建一个区块链全节点,然后通过访问本地的全节点获取并解析链上数据,再将清洗好的数据落入数据库。
不过这种方式成本是比较高的,对于个人来说实现起来比较困难。首先,我们需要一台性能不错的服务器,其次,按我们之前的计算,一个链一天会有100M以上的数据增量,这就要求有大量的存储空间,再者,完成整个流程也有一定的技术门槛。
完成数据的获取,清洗和落库之后,第二步是给地址打标签。我们知道,区块链是一个匿名的系统,通常我们并不知道这一串字符的背后,持有巨额财富的人到底是谁。但是我们做链上数据分析,最希望挖掘的信息就是地址间的关联。所以我们首先要做的是尽可能的找到地址背后的实体是谁。
给地址打标签一般有三种方法:最简单的方法是从一些公开的数据源获取。比如,比特币有www.walletexplorer.com这个网站,上面有大量比特币地址的标签,以太坊也可以通过https://etherscan.io/labelcloud拿到部分地址标签,其他区块链通常也能从他们的区块链浏览器拿到部分地址标签,但是越新的链标签越少。
第二种方法就是通过充值来获取地址标签。因为当前的区块链世界其实是以交易所为中心的,交易所控制了大部分的链上资金流向,弄清楚了交易所地址,就会对链上数据有比较清晰的全景图。当我们将币充进交易所后,我们可以根据交易所提供的充值地址追溯到交易所的热钱包地址甚至冷钱包地址。
第三种方法是根据前两种方法获得的地址标签去预测未知地址的标签。这里需要用到网络分析(如标签传播)机器学习(聚类,分类算法等)。基本的思路就是通过已知的地址标签和地址间的交易关系来进行预测。通过这种方式我们就可以得到一个交易所大致的地址池。
完成这些基础工作之后,第三步就是进一步的数据分析或运用。比如,我们可以做链上资金的流向监控,大额转账的预警,统计一个交易所持有的资产总额,建立数字货币的反洗钱系统等。这些信息不论对于数字货币的投资还是监管都是很有价值的。
Q3:上周刘毅老师聊到一些交易数据对量化投资和基本面投资很有价值,那链上数据在这两块有什么实际的指导价值?吴博士可以详细讲下吗?
这里我举两个例子来说明链上数据对数字货币投资的价值。
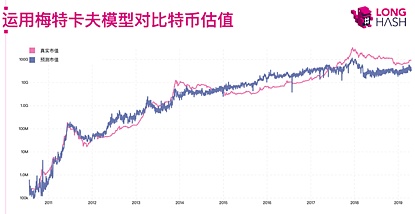
我先介绍一个偏基本面的估值模型:梅特卡夫定律。梅特卡夫定律最初是用于评估一个通信网络或者社交网络的价值,它认为网络的价值与其用户数量的平方成正比。我们之前提到,区块链本质是一个交易网络,因此运用梅特卡夫模型对数字货币进行估值也是合理的。
以比特币为例,首先我们需要从链上交易数据中统计出历史每日的活跃地址数,然后拿到对应时间的比特币市值,通过做对数-线性拟合建立比特币市值和活跃地址数之间的关系。这样我们就可以用该模型对比特币进行估值。当市值高于估值时,说明比特币高估,当市值低于估值时,说明比特币低估,这就可以给投资比特币提供参考。
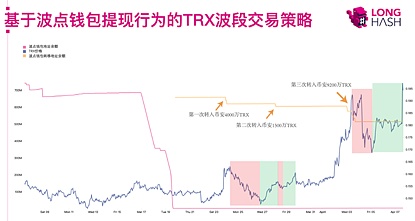
第二个例子是运用链上数据的事件驱动投资策略。波点钱包自称是波场官方合作的钱包,依靠承诺的高额“定存利息”和拉人头返现,钱包余额最高时曾达到 12 亿枚 TRX。2月中旬之后,波点钱包以主网升级为由停止了TRX充提现,钱包总余额一直维持在7.7亿个TRX左右。但是从 3 月 18 日开始,波点钱包在未告知用户的情况下,开始将所持有的TRX转入到10个新建地址。我们从波场链上数据分析追踪到此次波点钱包的大额转账行为共转出6.83亿枚TRX。
3月23日,波点钱包将新建地址中的4000万个TRX转入币安交易所,疑似砸盘套现。LongHash也对此进行了报道,并向投资者提示风险。
然后,波点钱包的疑似套现行为并没有就此结束。之后,波点钱包又进行了多次大额转出,目的地均为币安交易所。具体情况如下。
-
3月23日,波点钱包第一次大额提币,转移约4000万个TRX至币安交易所,币安TRX价格下跌9%,超过同期其他主流币种跌幅;随后上涨约6%;
-
3月28日,波点钱包第二次大额提币,转移约1500万个TRX至币安交易所,币安TRX价格下跌2%,超过同期其他主流币种跌幅;随后上涨约4%;
-
4月3日,波点钱包第三次大额提币,转移约9200万个TRX至币安交易所,币安TRX价格下跌12%,超过同期其他主流币种跌幅;随后上涨约16%;
当前波点钱包总共还有约5亿枚TRX。虽然TRX价格的下跌不一定由波点钱包的套现行为导致,但是从历史数据回测中,我们可以看到,它们之间的确展现出来某些相关性,这为我们做波段交易提供了机会。我们可以以波点钱包链上转出为信号,在期货市场做空TRX;当TRX价格平稳后,平仓TRX合约,并择机做多TRX现货。由于做空信号有很强的时效性,可做成程序化自动下单。
我们将波点钱包地址监控做成可视化的数据产品,大家感兴趣可以通过下面这个链接访问。https://www.longhash.com.cn/livecharts/point-function
Q4:我们知道LongHash除了做区块链的数据新闻之外,还发布了一些数据产品,您可以再解释下数据分析产品和他们的实际价值吗?
我介绍一下最近我们正在做的稳定币健康指数的数据产品。
由于加密货币价格的高波动风险,用户需要能够将加密货币快速、便捷套现的纽带。而稳定币作为对标法币、价格相对稳定的加密货币,可以方便不同币种与法币间的兑换,同时有利于投资者在加密货币市场的资金避险。特别是由于各国政府对加密货币的监管,许多国家都禁止法币与加密货币的直接交易,所以在这些国家,稳定币起着连接法币和加密货币的作用。因此,稳定币在加密货币交易中有着巨大的交易量。
但是稳定币存在超发诱惑、中心化供给端信任不足、去中心化稳定币的担保品市值不稳定和对公允价格的信任不足等痛点。去年,USDT因审计不公开、涉嫌超额发行、操纵比特币价格而饱受质疑,最终各种消息发酵,形成市场恐慌,致使USDT短时间出现了接近8%的折价。因此,用户对稳定币最重要的需求是稳定和保值。我们做稳定币的产品,重要的是帮助用户规避稳定币不稳定的风险。
综上,我们根据稳定币的不同维度的对比,编制稳定币的健康指数,直观反应稳定币的风险程度。我们选择了USDT、PAX、GUSD、TUSD、USDC这五种稳定币来分析。其中USDT是发行在比特币区块链Omni Layer上的代币,其余4种都是以太坊上的ERC20代币。因此,这5种稳定币的链上转账记录我们都能拿到。
我们从5个维度来对这5种稳定币进行分析和评估:稳定性、市场接受度、抗风险能力、成长性、实用性。
稳定性是从稳定币价格的折溢价程度和历史波动率来衡量,折溢价程度越低,波动率越小,我们认为稳定性就越高;
市场接受度需要考虑这5种稳定币的交易量占比、上交易所数量、交易对数量,这些指标越高,我们认为这个稳定币就越被接受;
抗风险能力我们统计各个交易所持有这5种稳定的数量。这里就需要用到我们之前提到的链上数据的分析方法,去拿到交易所地址的持币量。我们认为,一种稳定币在各个交易所分布的越分散,抗风险能力越强,反之,抗风险能力越弱。
成长性是从稳定币交易量占比和市值占比的变化趋势来分析,如果持续增长,说明成长性好。
最后一个维度是实用性,我们将其定义为该稳定币链上转账中与交易所无直接相关的转账数额占总转账数额的比例。如果这个比例越大,我们认为这些稳定币被用作非投资用途的比例就越高,实用性就越好。不过,按照我们的统计,超过50%的链上转账金额都与交易所直接相关。
Q5:链上数据现在有什么优点和弊端?链上数据怎么可以赋能现在的商业场景?
区块链以其可信任性、安全性和不可篡改性,让更多数据被解放出来,推进数据的海量增长。区块链的可追溯性使得数据从采集、交易、流通,以及计算分析的每一步记录都可以留存在区块链上,使得数据的质量获得前所未有的强信任背书,也保证了数据分析结果的正确性和数据挖掘的效果。这些优点使其在很多领域都有落地的场景。比如,在金融领域,链上数据天然具备了穿透监管的特性,即对资金来源和资金流向全过程的监控。在物联网领域,IoT设备的数据上链能够是其更安全和透明,并且可以对基于相互连接的智能设备之间服务交换的微交易带来便利。在供应链行业,可以运用链上数据来实现物品的可追溯,提高透明度。
说到链上数据当前的缺点,首先是数据标准不统一,不同的链有自己的数据格式,这会给数据分析带来很大障碍。另外,随着链上数据的不断增长,个人获取链上数据会变得更为困难。以后应该会出现专门提供链上数据的数据服务商。
Q6:在一些导航网站上看到收录了很多了数据分析的网站和产品,您怎么看未来链上数据的发展?
当前的链上数据,绝大部分都是交易和投资为目的产生的,链上的资金不是直接转入了交易所就是在去交易所的路上。不过,我还是很看好未来链上数据的发展。随着区块链技术的应用迅速发展,数据规模会越来越大,不同业务场景区块链的数据融合会进一步扩大数据规模和丰富性。从数据分析和挖掘的角度,通过把大数据AI技术与链上数据相结合,能让区块链中的数据更有价值,也能让大数据的预测分析落实为行动,使其共同成为数字经济时代的基石。