分布式系统入门指南
 浪花财经
浪花财经对于刚进入区块链领域的人来说,往往会对区块链技术感到非常困惑。理解该技术实际上相当简单的,但需要了解一些适当的背景知识。
此外,大多数人其实并不需要真正了解区块链的具体内部运作方式,而只需了解一些背景知识和指南。在这篇文章中,我将简要介绍分布式系统(Distributed System),讨论各种共识协议、网络模型的类型以及其他一些相关的想法。
对于想要了解这个领域的行业术语的人来说,这篇文章也可以算是一个指南,但我不会谈及太过晦涩难懂的细节内容。
01
时光倒流
分布式系统(Distributed Systems)是一个非常广泛的领域,为了便于理解,我将重点谈及该领域的共识方面。让我们把时间追溯到上世纪80年代。当时有一批非常聪明的计算机科学家正视图回答这一问题:如何才能让一组机器就某条消息(message)达成一致呢?我还是先来解释一下这个问题吧,因为这个问题似乎问得有点奇怪。
假设你有一个数据库,可以用来存储一些非常重要的数据(比如银行需要存储的财务信息)。由于这些数据决不能丢失,因此你会即刻尝试在很多其他的机器上复制存储这些数据,这些机器分别是m0,m1...mn。这样一来,如果其中任何一台机器出故障了,你也不会担心找不回数据。
为了搭建这个系统,我们可以采用最直观的方式,即:将其中一台机器指定为“首领(leader)”(假设由m0来担任leader这个角色),其他的机器为“追随者(followers)”。
如此一来,任何时候需要处理一笔新的客户交易时(如从Bob账户中扣除$10),leader机器将发出指令要求所有followers机器去执行这笔交易。这听起来很棒,可是我们会面临一个新的问题。
首先,如果leader机器m0发出指令要求m3机器从Bob的账户中扣除$10,但这条消息(message)发送失败了,并没有传递给m3,这怎么办呢?这真是很糟糕!我们无法再依靠m3机器来存储数据了,因为现在m3机器上存储了与其他机器上不一致的数据(inconsistent data)。要知道:不一致数据的出现就意味着,系统中有些机器中存储的数据与其他机器中存储的数据不一样,而它们本该是一样的!
02
确认消息
上述问题的一个基本解决方案是,确保m3机器已经收到消息。这就会涉及到了一个原子提交协议,即二阶段提交(2PC,Two-Phase-Commit)。之所以称之为原子提交协议,是因为这其中的理念是,如果需要提交事务(transaction),要么提交给系统中的所有机器,要么不提交给任何一台机器(...是的,我知道,这讲不太通)。
想象一下:机器m0并不会盲目地从客户端接收消息并将消息传递给其他机器,m0还会确保其他复制机在接收到消息之后会向m0确认自己已收到了该条消息。这很有道理,但是如果其中的某机器(假设是m6)出故障了,而其他的机器已经从Bob的账户中扣除了$10,这该怎么办呢?别担心,回滚(rollback)就可以了!
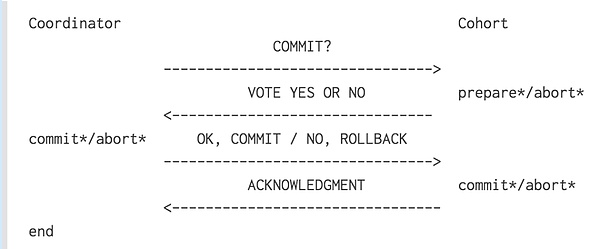
在两阶段提交协议中,系统一般包含两类机器(或节点):一类为协调者(coordinator),通常一个系统中只有一个;另一类为事务参与者(cohorts),一般包含多个,在数据存储系统中可以理解为多个数据副本。
顾名思义,两阶段提交协议由两个阶段组成。在正常的执行下,这两个阶段的执行过程如下所述:
阶段1:请求阶段(commit-request phase,或称表决阶段,voting phase)
在请求阶段,协调者将通知事务参与者准备提交或取消事务,然后进入表决过程。在表决过程中,参与者将告知协调者自己的决策:同意(事务参与者本地作业执行成功)或取消(事务参与者本地作业执行故障)。
阶段2:提交阶段(commit phase)
在该阶段,协调者将基于第一个阶段的投票结果进行决策:提交或取消。当且仅当所有的参与者同意提交事务时,协调者才通知所有的参与者提交事务,否则协调者将通知所有的参与者取消事务。参与者在接收到协调者发来的消息后将执行响应的操作。
如下图所示:
03
引入共识
精明的读者可能已经注意到我们构建的2PC / 3PC存在一些漏洞,比如,如果leader机器出现故障,则涉及到需要进行更换leader。但除此之外,还有一些更为紧迫的缺陷。(备注:3PC即三阶段提交(Three-phase commit),它是为解决两阶段提交协议的缺点而设计的,详情请参考:
首先,如果我们在系统中引入了另一个leader机器(假设是m1),会发生什么呢?我们需要这么做,以应对m0可能出现故障。但是,这会导致协调问题的出现,因为存在两个leader机器。假设Bob发送了两笔交易,其中一笔T1是“从Bob账户中扣除$10”,另一笔T2是“从Bob账户中扣除$20”,而Bob账户中恰好总共只有$20,这就麻烦了!
机器m0也许会将T1发布到网络中,而机器m1可能将T2发布出去。系统中的其他followers机器将根据这些操作的顺序来验证这两笔交易,并会出现不一致的状态(inconsistent states)。验证后,Bob账户里面还剩$10还是$0?就分布式系统而言,这真是太糟糕了!
其次,假设我们能够解决上文提到的leaders机器之间的协调问题。可是如果一些followers机器(节点)出现故障,那该咋办呢?要知道,这正是我们想要摆脱的问题。当有些节点出问题了,我们该怎么做呢?
如果我们静静等待这些节点重新上线,那我们可能面临一些效率问题,尤其是需要通过人为操作才能恢复某些服务器的时候。而如果我们选择忽视一些出故障的机器(节点),那我们应该忽视几台机器呢?更重要的是,假设某些机器恢复了,但它们的硬盘驱动器却因此而遭到了破坏(数据遭到损坏),这又该如何是好呢?虽然这些机器依旧会运行协议,但它们无法成功地将数据写入硬盘中。
预测种种这些问题都是很麻烦的,因此我们需要一个正在强劲的东西,能够忽视所有这些问题,只要保证一定数量的机器能够正常运行即可!就分布式系统而言,这真是太棒了。
上述这些问题(以及其他的问题)将我们带入了第一个共识协议 Paxos。这也让我们回到了最开始的那个问题:如何才能让一组机器就某条消息达成一致呢?由Leslie Lamport发明的Paxos是一种应对计算崩溃故障(crash fault)问题的共识协议。我不会深入讲解Paxos的运行方式,因为其中的细节实在是让人畏惧。
但是从更高的层面来看,Paxos其实是很好理解的:只要大多数的机器(节点)接受某个提议(proposal),则这将保证系统中所有的机器都不会出现不一致的状态。这是很神奇的,你只需要知道这点就可以了。
04
拜占庭容错
其实,这种应对机器故障的模型就是当前诸多数据中心(data centers)使用的模型。如果任何企业正在部署一个基于共识协议的分布式应用(distributed application),那该企业很有可能是在使用诸如Paxos这样的共识协议来作为应对机器故障的问题。
等等,那如果机器遭到黑客攻击了,该咋办呢?大多数企业都认为这不会发生,且平心而论,通过结合VPN(虚拟专用网络)、防火墙和其他的安全机制可能使黑客攻击基本上不太可能发生。但如果我们真的想要在遭受黑客攻击时保护自己,那么我们需要一个共识协议来应对系统中可能出现的(一台或多台)机器“说谎”的情况。这就引入了拜占庭式容错(BFT)。
为何叫拜占庭式呢?因为这个问题是Lamport在一个思维实验中提出的,一些拜占庭将军们面临的问题,他们被敌人的战线分开来了,但是依旧需要进行相互沟通来制定进攻/撤退计划。
05
一些行业术语
读到这,你也许会问“好吧,难道了解分布式系统只需要知道系统可能出现的机器(节点)故障问题(crash-fault)和拜占庭容错(BFT)就足够了吗?”差不多就是这样的。你真的没必要自找麻烦地去理解那些形式多样的各种共识协议,但你应该了解其中的一些基本分类:
1. Failure models 失效模型
-
机器故障:当机器(节点)出现故障时,共识协议就用于解决机器可能出现的状态不一致问题。
-
拜占庭容错:机器不仅可能出现故障,还可能会“撒谎”。
2. Network models 网络模型:
-
同步(Synchronous):我们不仅需要考虑机器会出现的各种故障问题,也要考虑网络通信的类型。在通信同步模型中,我们假设的是所有运行正常的节点(机器)都将在特定的时间内发送和接收消息。比如,你可以假定每条消息需要在5秒钟/分钟/小时内发送出去。
-
异步(Asynchronous):这是同步的对立面。即便对于运行正常的节点(correct nodes)来说,消息通信延迟问题依旧可能存在。这种情况带来的结果是:你无法判定到底是节点出现故障了,还是节点没有故障,只是需要长时间才能回应。
-
部分同步(Partially Synchronous):这种模型介于同步和异步之间。意思就是,存在一个上界(upper bound),但是这个上界并非被所有节点所知。我认为这种通信模型与实际的广域网通信(即互联网)非常相似。这只是我的个人观点哈,如果不同意见,欢迎反馈!
3. Message models 消息模型:
我将只考虑一种类型的消息模型:已验证的通信(authenticated communication),即各节点将对消息进行签名,任何人都可以验证来自某个其他节点的消息是真实可信的。
4. Guarantee models 保证模型:
这个命名有点奇怪,但我觉得这可以更好地描述该情况。
-
非概率性(Non-probabilistic):如果某个共识协议是非概率性的,就意味着该协议可以保证安全性(没有概率分布),只要一定数量的节点运行正常即可。
-
概率性(Probabilistic):如果某个共识协议是概率性的,那我们将自动引出一个概率分布(probability distribution)。通常来说,这种模型只能在1-ϵ的概率之间保证安全性,其中ϵ是系统设计人员选择的某个值。比如,一个概率性协议可能只保证99%的安全,即便一定数量的节点运行正常。记住这一点,这很重要!
06
区块链...或者,我真的不在乎你是谁
好的,我们先来回顾一下。共识协议实质上就是一些算法,这些算法允许我们在很多可能不信任的机器上部署一个数据库(也就是说,这些机器不相信任何一台机器会说真话,但相信大多数机器会说真话)。
在我们选择共识协议时,需要考虑到我们可能做出的各种假设,无论该协议是否处于同步设置,或者该协议是否会保证绝对安全或只是概率性地保证安全。
当我在上文中介绍Paxos时,我提到了节点对事务提交(proposals)进行投票。实际上,投票机制是唯一一种使用了数十年的机制。这种机制对于大多数情况都是适用的。
然而,假如我想公开地部署一个数据库,使任何人都可以加入并向系统提出交易(propose transactions)。此时会出现一个很大的问题:如果我允许任何人都可以进入我的系统,我将无法区分谁是谁。我不知道是谁正在参与进来。从根本来说,在过去,没有身份信息的共识是不可能实现的,但中本聪出现之后就不一样了。
比特币网络解决了这个问题。中本聪的绝妙观点在于,我们可以使用另一种机制来代替投票机制,即工作量证明机制(PoW)。比特币是首个实现不需要设想参与到网络中的到底是谁的共识协议。由于不需要确认身份,这使得可以很好地在一个无需许可的情况下部署比特币网络。
在比特币网络中,任何人都无需通过其他节点的允许便可加入该网络。在比特币网络中,节点不需要投票,而是提交附有砝码的值(propose values),该砝码就是工作量证明(PoW),用于解决一个加密难题(cryptographic puzzle)。所有的proposals都是联系在一起的,由这些proposals组成的最重的链(而非最长的链)构成了一个“正确的”历史记录。这就是比特币。
最后一点:比特币适合上文中所提到的哪一种模型?比特币使用的是拜占庭容错模型,该网络的通信是同步的,消息由密钥持有者进行验证,且保证模型是概率性的,就是说这条链是可以随时通过分叉进行复原的。换句话说,你可以接受“现在Bob的账户中只剩$10”,而你出错的几率很小。
这就是分布式系统的基本内容。在此基础上,你可以进入区块链世界了。
作者:Kevin Sekniqi
编译:Colin
原文链接:
https://sekniqi.com/blog/a-distributed-systems-primer-for-non-experts.html
【文章版权归原作者所有,其内容与观点不代表Unitimes立 场。编译文章仅为传播更有价值的信息,合作或授权请联系我们】